

Mặc dù thuật ngữ ‘Dự đoán gen’ (gene prediction) và ‘Chú giải gene’ (gene annotation) thường được sử dụng giống nhau nhưng thực ra thì chúng khác nhau. Ngoại trừ một số ngoại lệ, các chương trình dự đoán gen (gene predictor) tìm các đoạn trình tự có khả năng là đoạn trình tự chứa thông tin di truyền (coding sequence – CDS) của một gen và bỏ qua các vùng không được dịch mã (Untranslated region – UTR) hoặc các biến thể của chúng. Do đó, dự đoán gene dường như là một thuật ngữ không chính xác, dự đoán gen nên được thay bằng dự đoán vùng mã hóa thông tin di truyền ‘Cannonical CDS prediction’.
Việc chú giải gene thường bao gồm cả phần không được dịch mã UTR và các thuộc tính như dấu vết làm bằng chứng. Hình sau mô tả sự chú giải gene và các bằng chứng liên quan tới nó. Các thuật ngữ nằm trong ngoặc đơn là tên các phần mềm thông dụng cho việc lắp ghép các kiểu thông dụng của bằng chứng. Lưu ý sự chú giải gen (màu xanh nước biển) giải thích cả hai mẫu kết nối và 5′-3′ UTR được chỉ ra bởi các bằng chứng. Ngược lại, dự đoán gen mà được phần mềm SNAP đưa ra (màu xanh lá cây) là không chính xác vì thiếu exon 5′ của gen và vị trí bắt đầu sao mã, SNAP chỉ đưa ra dự đoán đó là một transcript đơn lẻ mà không có UTR.
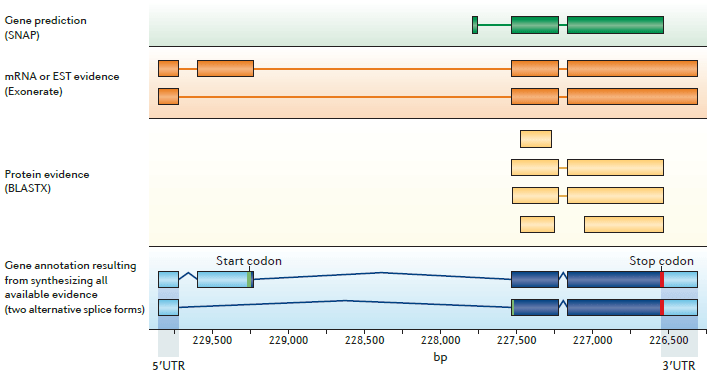
Do đó, chú giải gen phức tạp hơn dự đoán gen. Một quy trình cho việc chú giải hệ gen không chỉ xử lý với các loại bằng chứng không đồng nhất từ các mẫu của EST (expressed sequence tags), dữ liệu RNA-seq, tính đồng nhất của protein và dự đoán gen, mà nó còn phải tổng hợp tất cả các dữ liệu thành các mô hình gene tương đồng và sản sinh dữ liệu đầu ra để mô tả các kết quả của nó đủ chi tiết sao cho các kết quả này đáp ứng được yêu cầu để trở thành đầu vào cho genome browsers và cơ sở dữ liệu chú giải.
(Tham khảo từ A beginer’s guide to eukaryotic genome annotation | Nature Review)
LOBI Vietnam là công ty tiên phong trong lĩnh vực Đọc trình tự gen thế hệ mới NGS (Next Generation Sequencing) và Phân tích Tin sinh học. Liên hệ hotline/Zalo 092.510.8899 để biết thêm chi tiết.
