

- Tổng quan và đặt vấn đề
Tự thực bào (Autophagy) là một con đường lysosomal được bảo tồn tiến hóa và điều chỉnh chặt chẽ, giúp phân giải các đại phân tử như protein, glycogen, lipid và nucleotide. Quá trình tự thực bào được điều hòa chặt chẽ bởi sự phối hợp của các protein liên quan đến tự thực bào (ATGs), do đó, việc xác định chính xác các protein này là rất cần thiết để hiểu chức năng phân tử của chúng và phát triển các chiến lược điều trị cho các bệnh liên quan đến tự thực bào. Tự thực bào đóng vai trò quan trọng trong sự phát triển và biệt hóa của tế bào, đồng thời duy trì cân bằng nội môi sinh lý bệnh …. Nghiên cứu sâu hơn về tự thực bào là cần thiết để khám phá các chiến lược trị liệu mới cho nhiều loại bệnh lý và tình trạng sinh lý bệnh ở người, bao gồm các bệnh truyền nhiễm, tự miễn, chuyển hóa, thoái hóa thần kinh, tim mạch, thấp khớp, phổi và ác tính, cũng như lão hóa.
Theo truyền thống, việc xác định ATGs bao gồm phân tích các tính chất vật lý và hóa học thông qua các thí nghiệm trong phòng thí nghiệm “ướt” (wet-lab)…. Mặc dù hiệu quả, các phương pháp này thường tốn kém, tốn thời gian hoặc cả hai. Do đó, các phương pháp tính toán, đặc biệt là các phương pháp học máy truyền thống và các phương pháp học sâu phổ biến hiện nay, đã nhận được sự chú ý rộng rãi vì khả năng xác định ATGs nhanh chóng và hiệu quả với thông lượng cao.
Các phương pháp tính toán hiện tại, như ATGPred-FL4 và EnsembleDL-ATG5, vẫn còn tồn tại một số hạn chế. Chúng chủ yếu dựa vào các đặc trưng được tạo thủ công (handcrafted features), là các thuộc tính được chọn hoặc thiết kế thủ công từ chuỗi dựa trên kiến thức sinh học, nhưng thường không nắm bắt đầy đủ các mẫu và mối quan hệ phức tạp ẩn trong chuỗi protein. Ngoài ra, các mô hình ensemble như EnsembleDL-ATG, đòi hỏi tài nguyên tính toán đáng kể và có thể dễ bị overfitting do sự phức tạp của kiến trúc mạng nơ-ron sâu đa lớp của chúng. Do đó, vẫn còn nhiều dư địa để cải thiện hiệu suất dự đoán ATGs.
Những tiến bộ gần đây trong công nghệ xử lý ngôn ngữ tự nhiên (NLP) đã cách mạng hóa nhiều lĩnh vực, bao gồm tin sinh học. Các mô hình ngôn ngữ protein được đào tạo trước (PLMs) là một loại mô hình NLP sử dụng các kỹ thuật NLP bằng cách coi chuỗi protein như “câu”. Chúng được đào tạo trên các cơ sở dữ liệu chuỗi protein mở rộng theo cách tự giám sát, cho phép trích xuất các đặc trưng toàn diện chỉ dựa vào thông tin chuỗi. PLMs đã cho thấy thành công đáng kể trong nhiều nhiệm vụ liên quan đến protein, nhưng chưa được khám phá để dự đoán ATGs.
Bài viết này đề xuất một mô hình tính toán mới mang tên PLM-ATG nhằm giải quyết những hạn chế của các phương pháp hiện có và cải thiện việc xác định ATGs….
- Mô hình
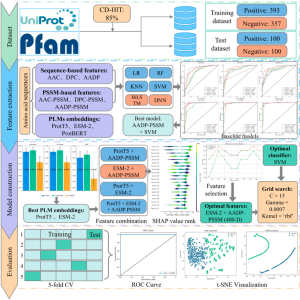
Trong nghiên cứu này, chúng tôi đề xuất mô hình tính toán mới gọi là PLM-ATG, tích hợp bộ phân loại máy học vector hỗ trợ (SVM) với sự kết hợp của các nhúng từ mô hình ngôn ngữ protein (PLM embeddings) và các đặc trưng dựa trên ma trận điểm vị trí cụ thể (PSSM-based features) để xác định ATGs chính xác….
Quá trình phát triển mô hình:
Đầu tiên, 36 mô hình cơ sở (baseline models) được xây dựng bằng cách trích xuất ba loại đặc trưng dựa trên chuỗi (AAC, DPC, AADP) và ba loại đặc trưng dựa trên PSSM (AAC-PSSM, DPC-PSSM, AADP-PSSM), và sử dụng sáu bộ phân loại khác nhau bao gồm các thuật toán học máy (LR, RF, SVM, KNN) và kiến trúc học sâu (BiLSTM, DNN)….
Tiếp theo, hiệu suất của ba loại nhúng PLM (ProtT5, ESM-2, ProtBERT) trong việc xác định ATGs được đánh giá và so sánh bằng cách huấn luyện các mô hình SVM trên tập dữ liệu thử nghiệm độc lập4…. ProtBERT embeddings bị loại bỏ do độ chính xác thấp nhất, và hai loại nhúng PLM còn lại (ESM-2 và ProtT5) được kết hợp với các đặc trưng AADP-PSSM để tiếp tục cải thiện việc dự đoán ATGs….
Thứ ba, để loại bỏ các đặc trưng dư thừa và không liên quan, phân tích SHAP được sử dụng để chọn tập con đặc trưng tối ưu từ sự kết hợp của nhúng ESM-2 và đặc trưng AADP-PSSM7…. Các đặc trưng được chọn này được sử dụng để huấn luyện mô hình SVM cuối cùng….
Các thành phần chính:
Bộ phân loại: Bộ phân loại SVM được chọn làm bộ phân loại chính vì hiệu suất vượt trội của nó trong các mô hình cơ sở và khả năng xử lý dữ liệu chiều cao hiệu quả2….
Đặc trưng dựa trên chuỗi: AAC (thành phần axit amin), DPC (thành phần dipeptide) và AADP (kết hợp AAC và DPC) được sử dụng để đặc trưng hóa chuỗi protein từ nhiều khía cạnh.
Đặc trưng dựa trên PSSM: AAC-PSSM, DPC-PSSM và AADP-PSSM được mở rộng từ các phương pháp trích xuất đặc trưng dựa trên chuỗi áp dụng cho ma trận PSSM, nhằm tích hợp thông tin tiến hóa quan trọng…. PSSM được tạo ra bằng cách tìm kiếm chuỗi protein tương đồng bằng PSI-BLAST11.
Nhúng PLM: Ba loại nhúng PLM (ProtT5, ESM-2, ProtBERT) được điều tra…. ESM-2 và ProtT5 cho thấy hiệu quả vượt trội và được sử dụng để kết hợp với các đặc trưng AADP-PSSM5…. Nhúng PLM mã hóa chuỗi protein thành các biểu diễn vector, với kích thước cố định thu được bằng cách lấy trung bình các nhúng của từng dư lượng axit amin. ProtT5 và ProtBERT có kích thước nhúng 1024, trong khi ESM-2 có kích thước 128027.
Lựa chọn đặc trưng: Phân tích SHAP được sử dụng để định lượng đóng góp của từng đặc trưng và xác định các đặc trưng quan trọng nhất từ tập kết hợp ESM-2 + AADP-PSSM16…. Tập con đặc trưng tối ưu (400 chiều) được chọn dựa trên hiệu suất trên tập thử nghiệm độc lập và hiệu quả tính toán….
Tập dữ liệu:
Nghiên cứu sử dụng tập dữ liệu ban đầu được xây dựng bởi Jiao et al. và Yu et al., bao gồm 493 mẫu dương (ATGs) được xác minh thực nghiệm từ UniProtKB và 493 mẫu âm (non-ATGs) từ Pfam
…. Các chuỗi tương đồng được loại bỏ (ngưỡng nhận dạng 85%)29. Tập dữ liệu được chia thành 80% tập huấn luyện/điều chỉnh tham số và 20% tập thử nghiệm độc lập để đánh giá không thiên vị. Sau khi loại bỏ 36 mẫu âm trùng lặp trong tập huấn luyện, kích thước cuối cùng của tập dữ liệu là: tập huấn luyện gồm 393 ATGs và 357 non-ATGs; tập thử nghiệm độc lập gồm 100 ATGs và 100 non-ATGs….
- Kết quả và Đánh giá
Hiệu suất của mô hình PLM-ATG được đánh giá trên tập thử nghiệm độc lập sử dụng sáu thước đo phổ biến: Accuracy (Acc), Precision (Pre), Sensitivity (Sen), Specificity (Spe), F1-score và Matthews correlation coefficient (MCC)…. Diện tích dưới đường cong ROC (AUC) cũng được tính toán….
Phân tích hiệu suất các mô hình cơ sở:
Các đặc trưng dựa trên PSSM luôn cho hiệu suất vượt trội so với các đặc trưng dựa trên chuỗi trên tất cả các mô hình…. Điều này là do thông tin tiến hóa được nhúng trong hồ sơ PSSM cung cấp các manh mối có giá trị cho việc xác định ATGs…. Bộ phân loại SVM cho thấy khả năng vượt trội khi kết hợp với từng loại đặc trưng, cho thấy SVM rất hiệu quả và đặc biệt phù hợp với nhiệm vụ này…. Sự kết hợp của SVM và AADP-PSSM là mô hình cơ sở tốt nhất xét về Acc (0.9750), MCC (0.9500) và Spe (0.9800)….


So sánh hiệu suất của ba loại nhúng PLM:
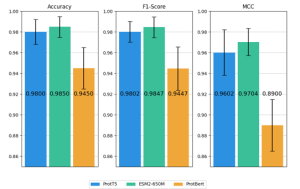
Các nhúng PLM (ESM-2, ProtT5, ProtBERT) được đánh giá bằng bộ phân loại SVM4…. ESM-2 đạt kết quả tốt nhất về Acc (0.9850), F1-score (0.9847) và MCC (0.9704)…. ProtT5 cho hiệu quả tương đương…. Ngược lại, ProtBERT hoạt động kém hơn hai loại nhúng PLM khác và thậm chí kém hơn cả các đặc trưng dựa trên PSSM truyền thống…. Dựa trên kết quả này, ProtT5 và ESM-2 được xác định là những ứng viên triển vọng nhất để phân tích thêm….
Phân tích hiệu suất lựa chọn đặc trưng:
Sự kết hợp của nhúng ESM-2 và đặc trưng AADP-PSSM cho hiệu suất tốt hơn và ổn định hơn so với các biểu diễn đặc trưng riêng lẻ và các tập đặc trưng kết hợp khác…. Hiệu suất của các tập đặc trưng kết hợp ProtT5+ESM-2 và ProtT5+ESM-2+AADP-PSSM kém hơn so với các nhúng PLM riêng lẻ, cho thấy các đặc trưng không liên quan hoặc dư thừa có tác động tiêu cực đến hiệu suất của mô hình….
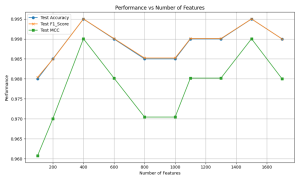
Phân tích SHAP được sử dụng để định lượng đóng góp của các đặc trưng trong tập ESM-2 + AADP-PSSM16…. Sau khi xếp hạng các đặc trưng theo giá trị SHAP của chúng, các tập con đặc trưng với các chiều khác nhau (K=1700, 1500, 1300, …, 100) được đánh giá…. Mô hình đạt hiệu suất cao nhất (Acc 99.50%) khi K = 400 và K = 150019…. Tập con đặc trưng 400 chiều được chọn cuối cùng để huấn luyện mô hình SVM, tạo ra mô hình PLM-ATG, cân nhắc sự cân bằng giữa hiệu suất và hiệu quả tính toán….
Hiệu suất của mô hình PLM-ATG cuối cùng:
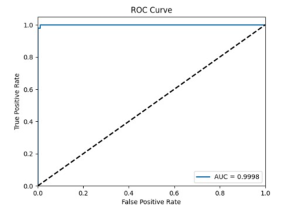
Mô hình PLM-ATG được đánh giá trên tập thử nghiệm độc lập. Đường cong ROC cho thấy giá trị AUC là 0.9998, cho thấy khả năng xác định ATGs gần như hoàn hảo…
Khả năng giải thích của mô hình PLM-ATG:
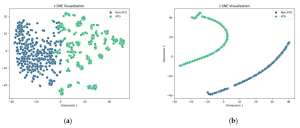
Để minh họa hiệu quả của bộ phân loại SVM và trực quan hóa các biểu diễn đặc trưng chiều cao, t-SNE được sử dụng…. Phân bố các đặc trưng ban đầu từ tập con 400-D ESM-2+AADP-PSSM trước khi huấn luyện cho thấy một mức độ chồng lấn giữa ATGs và non-ATGs…. Ngược lại, phân bố các đặc trưng ẩn cuối cùng được trích xuất bởi bộ phân loại SVM sau khi huấn luyện cho thấy các cụm tách biệt rõ ràng cho ATGs và non-ATGs trong không gian hai chiều…. Hình ảnh trực quan này cho thấy mô hình đã học thành công thông tin chính trong quá trình huấn luyện, giảm sự chồng lấn giữa các loại….
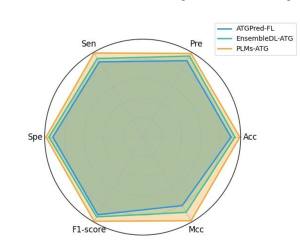
So sánh hiệu suất với các mô hình hiện có:
PLM-ATG được so sánh với hai công cụ tính toán hiện có trên cùng tập dữ liệu: ATGPred-FL và EnsembleDL-ATG45…. Mô hình PLM-ATG đề xuất thể hiện hiệu suất tiên tiến (state-of-the-art) với Acc 0.995, Pre 0.990, Sen 0.995, Spe 0.990, F1-score 0.995 và MCC 0.99048…. PLM-ATG đạt tỷ lệ cải thiện đáng kể (ví dụ: 5.0–9.0% Acc, 10–18% MCC) so với các phương pháp hiện có….
- Thảo luận và Hạn chế
Kết quả cho thấy các đặc trưng dựa trên PSSM vượt trội hơn các đặc trưng dựa trên chuỗi, nhấn mạnh tầm quan trọng của thông tin tiến hóa…. Bộ phân loại SVM được chứng minh là rất hiệu quả cho nhiệm vụ này, đặc biệt khi xử lý các tập dữ liệu nhỏ với các đặc trưng đơn giản, nơi các mô hình học sâu có thể gặp khó khăn…. Các nhúng PLM, đặc biệt là ESM-2 và ProtT5, có khả năng vượt trội hơn hẳn các biểu diễn đặc trưng truyền thống để dự đoán ATG5…. Việc kết hợp nhúng ESM-2 với đặc trưng AADP-PSSM là một chiến lược hiệu quả để cải thiện hiệu suất…. Tuy nhiên, các đặc trưng dư thừa hoặc không liên quan trong các tập kết hợp khác có thể ảnh hưởng tiêu cực đến hiệu suất mô hình…. Lựa chọn đặc trưng bằng SHAP là cần thiết để tối ưu hóa hiệu suất và hiệu quả tính toán, giúp mô hình đạt được hiệu suất cao nhất với tập con đặc trưng nhỏ hơn….
Về hiệu quả tính toán, PLM-ATG đạt được sự cân bằng tốt giữa hiệu suất và hiệu quả…. Giống như ATGPred-FL, PLM-ATG sử dụng SVM nhẹ cho phép dự đoán nhanh chóng dựa trên CPU…. Tuy nhiên, việc trích xuất nhúng ESM-2 yêu cầu khoảng 8GB RAM trong quá trình tiền xử lý ngoại tuyến…. Ngược lại, EnsembleDL-ATG đòi hỏi tăng tốc GPU trong cả quá trình huấn luyện và dự đoán…. Điều này làm cho PLM-ATG trở thành một công cụ mạnh mẽ, hiệu quả và đầy hứa hẹn cho nghiên cứu tự thực bào….
Một điểm quan trọng là việc phát hiện và loại bỏ 36 mẫu âm trùng lặp trong tập dữ liệu huấn luyện ban đầu được sử dụng trong các nghiên cứu trước24…. Việc này giúp duy trì tính toàn vẹn của tập dữ liệu và cải thiện độ chính xác của mô hình.
Mặc dù PLM-ATG đã đạt hiệu suất gần như hoàn hảo trong việc xác định ATGs, bài viết đề cập rằng những nỗ lực trong tương lai nên tập trung vào việc nghiên cứu sâu hơn về ATGs và chức năng của chúng. Đây có thể được coi là một định hướng cho nghiên cứu trong tương lai hơn là một hạn chế của mô hình hiện tại. Tuy nhiên, yêu cầu về RAM để trích xuất nhúng ESM-2 có thể là một hạn chế thực tế đối với một số người dùng.
- Kết luận
Nghiên cứu này đã đề xuất một mô hình tính toán mới mang tên PLM-ATG để xác định các protein liên quan đến tự thực bào (ATGs). PLM-ATG tích hợp bộ phân loại SVM với sự kết hợp của nhúng từ mô hình ngôn ngữ protein (ESM-2) và các đặc trưng dựa trên PSSM (AADP-PSSM) sau khi thực hiện lựa chọn đặc trưng tối ưu.
Kết quả đánh giá trên tập thử nghiệm độc lập cho thấy PLM-ATG hoạt động tốt trong nhiệm vụ xác định ATG và đạt được tiến bộ đáng kể so với các mô hình tiên tiến hiện có. Sự kết hợp của các đặc trưng từ PLM embeddings và PSSM-based features, cùng với khả năng phân loại mạnh mẽ của SVM và lựa chọn đặc trưng hiệu quả, đã đóng góp vào hiệu suất vượt trội của mô hình.
PLM-ATG nổi lên như một công cụ mạnh mẽ, hiệu quả và đầy hứa hẹn để thúc đẩy nghiên cứu tự thực bào. Để tạo điều kiện thuận lợi cho các nhà nghiên cứu sử dụng mô hình, một máy chủ web thân thiện với người dùng đã được xây dựng và có thể truy cập công khai…. Dữ liệu và mã nguồn tương ứng cũng được công khai trên GitHub….
Hơn nữa, các phương pháp và hiểu biết sâu sắc được trình bày trong nghiên cứu này cung cấp một tài liệu tham khảo có giá trị cho việc phát triển các mô hình dự đoán trong các lĩnh vực liên quan đến protein khác, khẳng định tác động biến đổi của công nghệ NLP đối với tin sinh học. Mặc dù hiệu suất hiện tại rất cao, nghiên cứu tương lai nên tập trung vào việc nghiên cứu sâu hơn về chức năng của ATGs.
LOBI Vietnam là công ty tiên phong trong lĩnh vực Đọc trình tự gen thế hệ mới NGS (Next Generation Sequencing) và Phân tích Tin sinh học. Liên hệ hotline/Zalo 092.510.8899 để biết thêm chi tiết.
