

MỤC LỤC BÀI VIẾT
Tổng quan và Đặt vấn đề
- Dữ liệu trình tự RNA đơn bào (single-cell RNA sequencing – scRNA-seq) và trình tự RNA đơn nhân (single-nucleus RNA sequencing – snRNA-seq) đã tạo ra hàng trăm triệu hồ sơ tế bào người trên khắp các cơ quan, bệnh tật, giai đoạn phát triển và các điều kiện khác nhau. Việc phân tích các bản đồ tế bào ngày càng lớn này có tiềm năng tiết lộ mối liên hệ giữa tế bào và bệnh tật, xác định các trạng thái tế bào trong các ngữ cảnh mô không ngờ tới, và liên kết sinh học in vivo (trong cơ thể) với các mô hình in vitro (trong phòng thí nghiệm).
- Tuy nhiên, các mô hình hiện tại chưa được thiết kế để tìm kiếm các hồ sơ tế bào tương đồng trên quy mô lớn giữa các tập dữ liệu khổng lồ.Việc phân tích trên toàn cơ thể và giữa các tập dữ liệu khác nhau gặp khó khăn do thách thức trong việc quản lý và hài hòa dữ liệu, khó khăn trong việc định nghĩa biểu diễn chiều thấp chung, thiếu các thước đo chính xác để so sánh giữa các hồ sơ tế bào, và thiếu phương pháp tìm kiếm hồ sơ tế bào hoàn chỉnh.
- Để khai thác được quy mô và sự phong phú của các bản đồ tế bào, cần có (1) một mô hình nền tảng về trạng thái tế bào với biểu diễn hiệu quả và có thể sử dụng trên nhiều ứng dụng mà không cần huấn luyện lại, và (2) một thước đo sự tương đồng tế bào mạnh mẽ trước nhiễu kỹ thuật, có khả năng mở rộng đến hàng trăm triệu tế bào và tổng quát hóa cho dữ liệu và trạng thái tế bào chưa được quan sát trong quá trình huấn luyện.
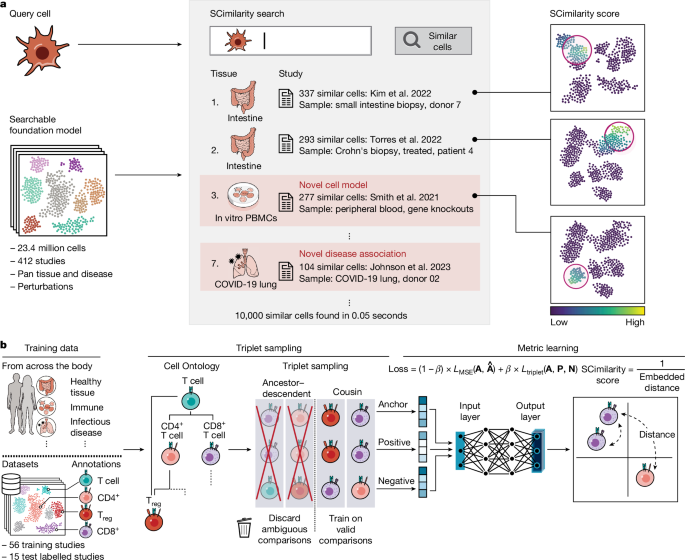
- SCimilarity được phát triển như một mô hình nền tảng dựa trên học metric sâu nhằm giải quyết những vấn đề này, bằng cách học một biểu diễn thống nhất và có thể giải thích được để cho phép truy vấn nhanh chóng hàng chục triệu hồ sơ tế bào tìm kiếm các tế bào tương đồng về phiên mã
Mô hình SCimilarity
- Định nghĩa: SCimilarity là một mô hình nền tảng học metric sâu giúp định lượng sự tương đồng giữa các hồ sơ đơn bào.
Hàm mất mát
- SCimilarity kết hợp học biểu diễn không giám sát và học metric có giám sát bằng cách tối ưu hóa đồng thời hai hàm mất mát.
- Hàm mất mát Triplet (Triplet Loss): Đây là thành phần học metric có giám sá. Nó được sử dụng để nhúng các hồ sơ biểu hiện gen từ các loại tế bào phù hợp ở gần nhau, giúp tích hợp các tế bào cùng loại trên các nghiên cứu khác nhau. Quá trình huấn luyện sử dụng các bộ ba tế bào (triplet), mỗi bộ gồm một tế bào “neo” (anchor), một tế bào “dương” (positive – tương đồng với neo), và một tế bào “âm” (negative – khác với neo), dựa trên các chú thích loại tế bào chuẩn hóa từ Cell Ontology. SCimilarity loại trừ các mối quan hệ phân cấp không rõ ràng trong Cell Ontology khỏi quá trình lấy mẫu triplet để đảm bảo sự khác biệt là rõ ràng. Mô hình sử dụng kỹ thuật “khai thác triplet bán khó” (semi-hard triplet mining) để chọn các triplet cung cấp thông tin hiệu quả nhất cho việc cập nhật mô hình. Nhúng vào không gian siêu cầu (hypersphere) được sử dụng để đảm bảo tính nhất quán của biên (margin) trong quá trình huấn luyện triplet loss.
- Hàm mất mát tái tạo MSE (Mean Squared Error): Đây là thành phần học biểu diễn không giám sát. Nó khuyến khích mô hình giữ lại các biến thể tinh tế hơn trong các mẫu biểu hiện gen trong cùng một loại tế bào.
- Hàm mất mát kết hợp: SCimilarity sử dụng hàm mất mát kết hợp trọng số giữa triplet loss và MSE loss (tham số β). Mô hình được lựa chọn (với β=0.001) là mô hình kết hợp tốt nhất giữa hiệu suất truy vấn và tích hợp dữ liệu.
Dữ liệu Huấn luyện
Mô hình được huấn luyện trên một tập dữ liệu lớn và đa dạng gồm 23.4 triệu hồ sơ tế bào từ 412 nghiên cứu. Tập dữ liệu huấn luyện cụ thể được sử dụng để lấy mẫu triplet bao gồm 7,886,247 hồ sơ từ 56 nghiên cứu có chú thích loại tế bào chuẩn hóa theo Cell Ontology. Dữ liệu chủ yếu từ nền tảng 10x Genomics Chromium. Các mẫu khối u, dòng tế bào và tế bào gốc cảm ứng đa năng (iPSC) đã bị loại khỏi tập huấn luyện và kiểm tra.
Khả năng và Tính năng chính
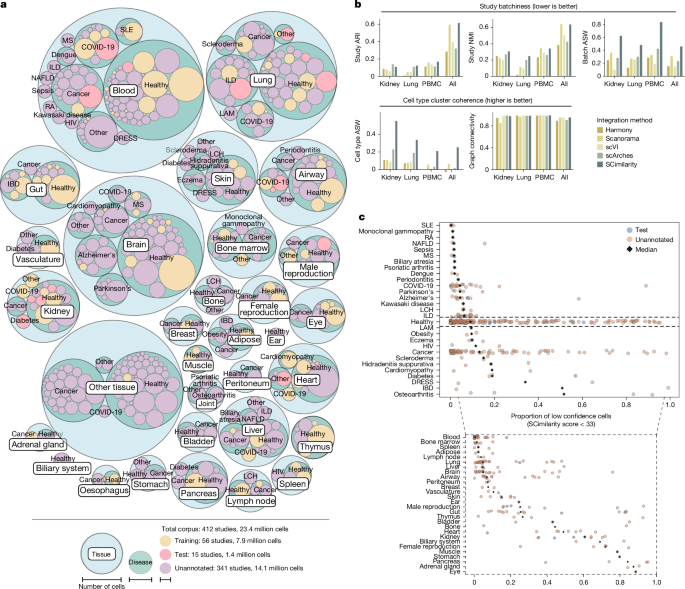
- Tìm kiếm quy mô lớn: Cho phép truy vấn hiệu quả hàng chục triệu hồ sơ tế bào. Việc tìm kiếm láng giềng gần nhất (k-NN) được tối ưu hóa để rất nhanh chóng.
- Định lượng tương đồng: Cung cấp “điểm SCimilarity” (SCimilarity score), là nghịch đảo khoảng cách cosine của hai hồ sơ tế bào được nhúng, để đo lường sự tương đồng.
- Tổng quát hóa: Biểu diễn được học có khả năng áp dụng cho các tập dữ liệu, trạng thái tế bào và nền tảng công nghệ (ngoài 10x Genomics Chromium) chưa từng thấy trong quá trình huấn luyện.
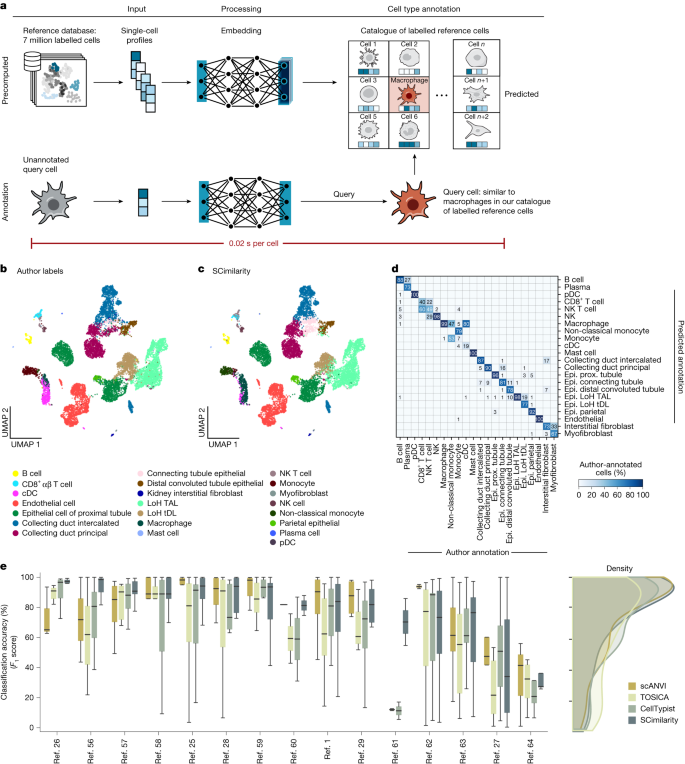
- Chú thích loại tế bào: Có thể chú thích loại tế bào bằng cách tìm kiếm các tế bào tương đồng nhất trong tập dữ liệu tham chiếu đã chú thích (sử dụng k-NN). Phương pháp này đạt hiệu suất cạnh tranh với các công cụ chú thích chuyên biệt.
- Tích hợp dữ liệu: Học một biểu diễn chung giúp tích hợp dữ liệu từ các nghiên cứu khác nhau mà không cần các phương pháp điều chỉnh batch (batch correction) chuyên biệt. Nó duy trì sự gắn kết của các cụm loại tế bào.
- Giải thích (Explainability): Sử dụng khuôn khổ Integrated Gradients để xác định các gen quan trọng nhất đóng góp vào sự khác biệt giữa các hồ sơ tế bào hoặc trạng thái tế bào. Các gen quan trọng này thường tương ứng tốt với các gen dấu ấn (marker gene) đã biết.
- Phát hiện ngoại lai (Outlier Detection): Cung cấp một mức độ tin cậy cho biểu diễn của mỗi tế bào, cho phép xác định các tế bào có khả năng là ngoại lai hoặc không được biểu diễn tốt bởi mô hình (ví dụ: khác biệt lớn so với dữ liệu huấn luyện).
Ứng dụng
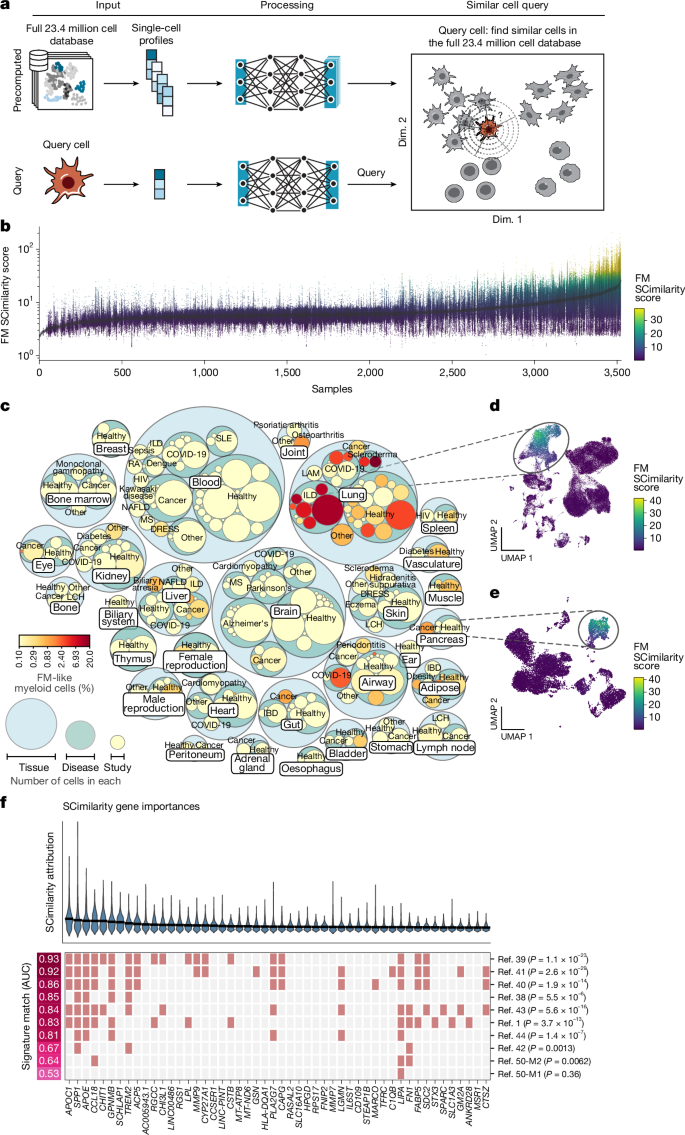
Tìm kiếm tế bào liên quan đến xơ hóa (FM)
Sử dụng SCimilarity để tìm kiếm các tế bào đại thực bào liên quan đến xơ hóa (FM) trong bản đồ 23.4 triệu tế bào. Tìm thấy các tế bào tương đồng FM phổ biến trong mẫu phổi ILD và COVID-19, cũng như có mặt trong một số loại ung thư (uveal melanoma, PDAC, ung thư ruột kết) và các bệnh/mô xơ hóa khác. Tỷ lệ FM thay đổi tùy theo bệnh.
Myofibroblasts
Việc tìm kiếm myofibroblasts liên quan đến xơ hóa cho thấy sự hiện diện của chúng tương quan với FM trong các bộ dữ liệu ILD, COVID-19 và PDAC.
Gen quan trọng cho FM
Phân tích gen quan trọng bằng Integrated Gradients cho FM làm giàu các quá trình liên quan đến xơ hóa, chuyển hóa lipid và nhận diện tổn thương, chồng lấn đáng kể với các dấu hiệu đã công bố.
Xác định mô hình in vitro
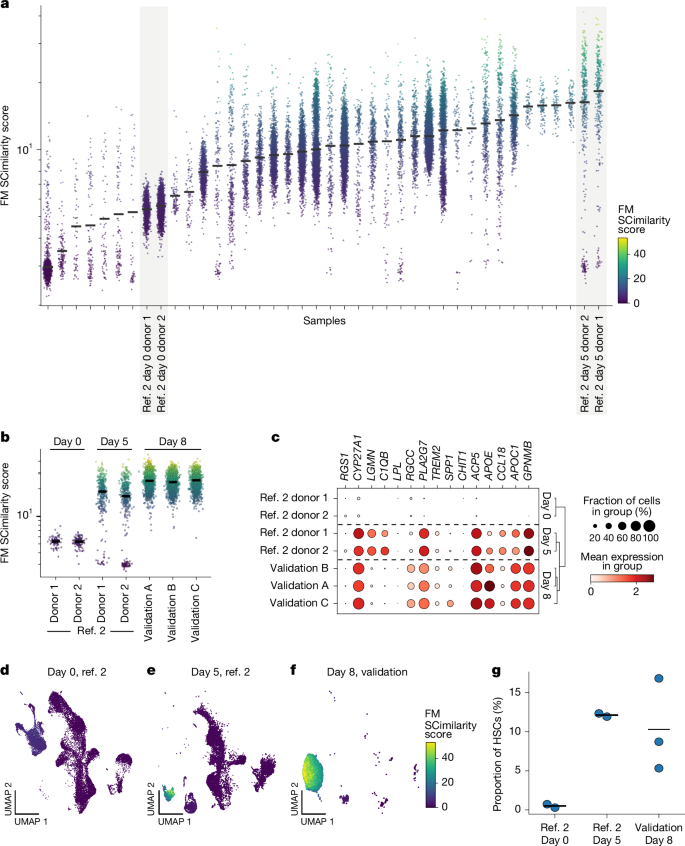
Sử dụng SCimilarity để tìm kiếm tế bào giống FM trong các mẫu in vitro. Đã xác định được một hệ thống nuôi cấy hydrogel 3D ban đầu được thiết kế để mở rộng tế bào gốc tạo máu (HSC) lại tạo ra các tế bào tương tự FM. Kết quả này đã được xác thực thực nghiệm, cho thấy khả năng của SCimilarity trong việc xác định các điều kiện thực nghiệm để tái tạo các trạng thái tế bào mong muốn.
Thảo luận và Hạn chế
Thảo luận
SCimilarity cung cấp một cách tiếp cận độc đáo dựa trên học metric cho phép tìm kiếm tế bào trên quy mô lớn. Người dùng có thể định nghĩa truy vấn bằng nhiều cách (tế bào đơn lẻ, tâm điểm cụm, v.v.) và SCimilarity đánh giá tính nhất quán của truy vấn. Việc sử dụng hồ sơ biểu hiện gen đầy đủ giúp nắm bắt sự phức tạp của tế bào mà không cần dựa vào các dấu ấn gen được tuyển chọn chủ quan, mặc dù SCimilarity cũng có thể suy ra các dấu ấn gen quan trọng. Công cụ được cung cấp dưới dạng API Python mã nguồn mở, cho phép người dùng tùy chỉnh truy vấn và lọc kết quả dựa trên siêu dữ liệu hoặc điểm tương đồng. SCimilarity tạo tiền đề cho việc khám phá có hệ thống các quần thể tế bào tương đồng về phiên mã trên Bản đồ tế bào người, giúp xác nhận sự tồn tại của các quần thể trên nhiều nghiên cứu, kết nối các nghiên cứu độc lập và xác định các ngữ cảnh hoạt động của cùng một quần thể. Nó được báo cáo là hoạt động hiệu quả hơn các mô hình nền tảng trước đây (scFoundation, scGPT) trong việc xác định các tế bào tương đồng với trạng thái truy vấn (FM, myofibroblasts). Mô hình có khả năng tổng quát hóa cho dữ liệu và tế bào chưa thấy trong huấn luyện, không cần huấn luyện lại cho các nhiệm vụ như chú thích loại tế bào hoặc truy vấn tế bào. Mặc dù chủ yếu được huấn luyện trên dữ liệu 10x Genomics Chromium, nó vẫn hoạt động hiệu quả với dữ liệu từ các nền tảng scRNA-seq khác.
Hạn chế và Cân nhắc
- Kết quả truy vấn phụ thuộc vào hồ sơ đầu vào được sử dụng, và chất lượng của kết quả cuối cùng phụ thuộc vào giả định và chất lượng của hồ sơ đầu vào. Việc lựa chọn các tế bào đầu vào có thể mang tính chủ quan và ảnh hưởng đến phân tích tiếp theo. SCimilarity cung cấp công cụ để đánh giá tính nhất quán của truy vấn, nhưng quyết định vẫn thuộc về người dùng.
- Khả năng chú thích loại tế bào bị giới hạn bởi các thuật ngữ Cell Ontology có sẵn và các trạng thái tế bào đã được quan sát và chú thích trong dữ liệu huấn luyện.
- Một số loại tế bào cụ thể có thể không được biểu diễn tốt trong mô hình hiện tại, đặc biệt là các tế bào bị loại trừ khỏi quá trình huấn luyện (ví dụ: tế bào khối u, dòng tế bào, iPSCs) hoặc ít đại diện/có chú thích không rõ ràng trong dữ liệu huấn luyện (ví dụ: mẫu bào thai, bạch cầu hạt, tế bào gốc tạo máu và tiền thân, trạng thái tế bào tiền thân trung gian do tính mơ hồ trong cam kết dòng dõi).
- Tích hợp dữ liệu giữa các công nghệ khác nhau cần được diễn giải cẩn thận, mặc dù mô hình tổng quát hóa tốt.
- Tồn tại các mẫu dữ liệu trùng lặp trong tập dữ liệu tham chiếu đầy đủ do việc tích hợp nguyên vẹn các tập dữ liệu đã xuất bản.
- Hiệu suất của mô hình trên các nhiệm vụ khác ngoài truy vấn và tích hợp cần được đánh giá trong các nghiên cứu tương lai.
Kết luận
- SCimilarity là một công cụ mạnh mẽ dựa trên học metric sâu, được thiết kế đặc biệt để giải quyết thách thức về tìm kiếm có khả năng mở rộng các hồ sơ tế bào tương đồng trong các bản đồ tế bào người ngày càng lớn.
- Mô hình học một biểu diễn phổ quát và có thể giải thích được, cho phép định lượng sự tương đồng và tổng quát hóa tốt cho dữ liệu và trạng thái tế bào chưa thấy trước đây.
- Khả năng truy vấn hiệu quả hàng chục triệu hồ sơ, cùng với các tính năng như chú thích loại tế bào, tích hợp dữ liệu, giải thích gen quan trọng và phát hiện ngoại lai, làm cho SCimilarity trở thành một nguồn lực quý giá cho cộng đồng nghiên cứu đơn bào.
- Các ứng dụng minh họa, như việc xác định các tế bào đại thực bào liên quan đến xơ hóa (FM) trên khắp các bệnh và mô, và việc phát hiện một hệ thống nuôi cấy in vitro tái tạo trạng thái tế bào mong muốn, chứng minh tiềm năng của SCimilarity trong việc tạo ra hiểu biết sinh học sâu sắc và các giả thuyết có thể kiểm chứng thực nghiệm từ Bản đồ tế bào người.
- Khi Bản đồ tế bào người tiếp tục phát triển và các biểu diễn SCimilarity lớn hơn được huấn luyện, mô hình này sẽ cho phép truy vấn và tìm kiếm trên các khía cạnh rộng lớn hơn của sinh học con người.

Tài liệu tham khảo: https://www.nature.com/articles/s41586-024-08411-y
LOBI Vietnam là công ty tiên phong trong lĩnh vực Đọc trình tự gen thế hệ mới NGS (Next Generation Sequencing) và Phân tích Tin sinh học. Liên hệ hotline/Zalo 092.510.8899 để biết thêm chi tiết.
