

Mở đầu
Việc phân loại trình tự DNA là một nhiệm vụ cực kỳ quan trọng trong tin sinh học, đóng vai trò thiết yếu trong việc hiểu và xác định sự khác biệt di truyền giữa các loài khác nhau. Điều này thúc đẩy nghiên cứu và bảo tồn đa dạng sinh học. Với sự phát triển của công nghệ giải trình tự thông lượng cao, lượng dữ liệu bộ gen khổng lồ đã được tạo ra. Tuy nhiên, trong các nghiên cứu siêu bộ gen, nhiều trình tự bị mất trong quá trình lắp ráp và phân loại contig, khiến chỉ một phần nhỏ được phân loại chính xác bằng các công cụ hiện có. Để phân loại trình tự DNA hiệu quả, cần đạt được độ chính xác, độ thu hồi cao và hiệu quả tính toán.
Các phương pháp truyền thống để phân loại trình tự DNA thường dựa vào kỹ thuật căn chỉnh (alignment-based), trong đó trình tự DNA chưa biết được so sánh với các trình tự tham chiếu trong cơ sở dữ liệu. Các công cụ như BLAST, MMseqs2, MMseqs2 taxonomy, và minimap2 là những ví dụ điển hình. Mặc dù các phương pháp này có thể xác định mối quan hệ phân loại bằng cách căn chỉnh trình tự chưa biết với tham chiếu, hiệu suất của chúng lại nhạy cảm với chất lượng và phạm vi bao phủ của cơ sở dữ liệu. Cơ sở dữ liệu hiện tại chỉ bao phủ một phần nhỏ các loài đã biết, gây khó khăn trong việc xác định trình tự tương đồng cho nhiều trình tự DNA. Hơn nữa, các công cụ dựa trên căn chỉnh thường có hiệu quả tính toán thấp hoặc tỷ lệ thu hồi thấp.
Để khắc phục sự phụ thuộc vào chất lượng dữ liệu, các nhà nghiên cứu đã chuyển trọng tâm sang các phương pháp Học máy (Machine Learning – ML). Các phương pháp ML học các mẫu tiềm ẩn từ dữ liệu bằng các kỹ thuật mã hóa như đếm k-mer hoặc mã hóa thứ tự. Các phương pháp ML ban đầu sử dụng các bộ phân loại như máy vector hỗ trợ, cây quyết định và rừng ngẫu nhiên. Tuy nhiên, các kỹ thuật mã hóa truyền thống thường không thể xử lý các trình tự dài hoặc hy sinh thông tin cấu trúc và trình tự.
Sự trỗi dậy của Học sâu và Biểu diễn Hình ảnh (FCGR)
Nhận thấy khả năng vượt trội của Học sâu (Deep Learning – DL) trong việc nhận diện các mẫu phức tạp so với ML, các phương pháp DL ngày càng được áp dụng thường xuyên hơn cho phân loại trình tự DNA. Các phương pháp này thường dựa vào các biểu diễn trình tự DNA, ví dụ như k-mer, mã hóa one-hot, và Word2Vec, làm đầu vào cho mạng. Tuy nhiên, các biểu diễn này hoặc không giữ được thông tin cấu trúc vốn có hoặc bị giới hạn ở các trình tự có độ dài cố định.
Để giải quyết vấn đề độ dài trình tự tùy ý, Biểu diễn Trò chơi Hỗn loạn Tần số (Frequency Chaos Game Representation – FCGR) được giới thiệu. FCGR chuyển đổi các trình tự DNA có độ dài bất kỳ thành các hình ảnh có kích thước cố định bằng cách xây dựng các hồ sơ tần số, gói gọn các thuộc tính thống kê và các mẫu. Kỹ thuật này thoát khỏi ràng buộc về độ dài trình tự trong khi vẫn giữ lại nhiều thông tin trình tự hơn so với các biểu diễn khác. Rizzo et al. là những người đầu tiên biểu diễn trình tự DNA dưới dạng hình ảnh bằng cách sử dụng FCGR.
Tuy nhiên, các nghiên cứu hiện tại chỉ chủ yếu xem xét thông tin cục bộ trong hình ảnh FCGR, bỏ qua các phụ thuộc tầm xa và thông tin ngữ cảnh toàn cục. Mặc dù các mạng nơ-ron tích chập (Convolutional Neural Networks – CNNs) đã được sử dụng để xử lý FCGR và mã hóa thông tin cục bộ, chúng thường bỏ qua thông tin toàn cục, vốn rất quan trọng để hiểu các đặc điểm và chức năng của trình tự. Do trường tiếp nhận cục bộ bị hạn chế, các phương pháp dựa trên CNN gặp khó khăn trong việc nắm bắt các phụ thuộc toàn cục và khai thác đầy đủ các tính năng tiềm năng của FCGR.
Để hiểu một cách toàn diện các mẫu trong trình tự DNA, mô hình cần nắm bắt đồng thời thông tin cục bộ và toàn cục.
Giới thiệu PCVR: Kết hợp FCGR, ViT và MAE Pre-training
Vậy nên nhiều nơi đã đề xuất PCVR, một Biểu diễn Thị giác Theo ngữ cảnh Được Huấn luyện Trước (Pre-trained Contextualized Visual Representation) để phân loại trình tự DNA. PCVR mã hóa FCGR bằng Vision Transformer (ViT) thành các tính năng theo ngữ cảnh chứa nhiều thông tin toàn cục hơn. Đây là phương pháp đầu tiên giới thiệu ViT để trích xuất biểu diễn thị giác theo ngữ cảnh của trình tự DNA, nắm bắt thông tin ngữ cảnh toàn cục và các phụ thuộc tầm xa.
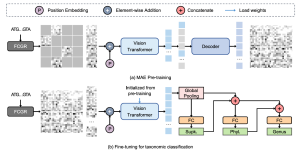
Hình 1, nằm trong phần Phương pháp, minh họa quy trình phân loại trình tự DNA bằng PCVR. Quy trình này bao gồm hai giai đoạn: giai đoạn huấn luyện trước MAE để học các tính năng mạnh mẽ và giai đoạn tinh chỉnh để phân loại phân loại học. Phần trên (a) của Hình 1 mô tả quá trình huấn luyện trước tự giám sát MAE, giúp ViT encoder có khả năng nhận diện mạnh mẽ các hình ảnh thông qua việc học tái tạo và thu được PCVR. Phần dưới (b) của Hình 1 cho thấy giai đoạn tinh chỉnh, mô tả cấu trúc tinh chỉnh tính năng phân cấp dựa trên PCVR đã học được.
- Biểu diễn Trình tự DNA: Trong PCVR, trình tự DNA được nhúng vào FCGR. Kỹ thuật này giải quyết các thách thức như độ dài trình tự khác nhau, quá dài hoặc quá ngắn. Khác biệt chính giữa FCGR và mã hóa đếm k-mer là FCGR ánh xạ trình tự DNA thành một ma trận 2 chiều bằng cách sử dụng phương pháp CGR, nắm bắt thông tin mẫu và cấu trúc phong phú hơn so với kỹ thuật đếm k-mer 1 chiều và các kỹ thuật mã hóa 1 chiều khác.

Hình 2, nằm trong phần Phương pháp, hiển thị quy trình nhúng FCGR của trình tự DNA trong PCVR. Trong CGR, mỗi trình tự con nucleotide dài k trong trình tự được chuyển đổi thành một điểm trên hình ảnh vuông đơn vị một cách tuần tự. Tọa độ của nucleotide hiện tại phụ thuộc vào tọa độ của nucleotide trước đó. Sau đó, CGR được lượng tử hóa thành một hình ảnh với độ phân giải 2^k x 2^k, trong đó mỗi pixel được tô bóng dựa trên tần số của trình tự con nucleotide dài k liên quan trong đoạn trình tự. Số lượng mỗi k-mer xuất hiện trong trình tự được đếm. Cuối cùng, các số đếm này được chuyển đổi thành tần số và mỗi pixel trong FCGR được tô bóng theo tần số của nó. - Biểu diễn Theo ngữ cảnh với Vision Transformer (ViT): Sau khi trình tự DNA được chuyển đổi thành nhúng FCGR, các nhúng này được sử dụng để trích xuất các mẫu phân biệt và tiết lộ các tính năng trình tự theo ngữ cảnh. ViT, một mô hình đơn giản nhưng mạnh mẽ chuyển transformer từ lĩnh vực NLP sang lĩnh vực thị giác máy tính, có khả năng học các mối quan hệ toàn cục trong hình ảnh và trích xuất tính năng ở nhiều tỷ lệ khác nhau. FCGR gói gọn cả thống kê trình tự DNA toàn cục và các mẫu k-mer ngắn được cục bộ hóa. Tận dụng thuộc tính này, ViT mô hình hóa hiệu quả các tính năng trình tự theo ngữ cảnh, tạo thành xương sống của framework PCVR.
ViT bao gồm nhúng token và mã hóa sử dụng transformer encoder. Transformer encoder bao gồm cơ chế tự chú ý đa đầu (Multi-head Self-Attention – MHSA) và mạng chuyển tiếp đầy đủ kết nối theo vị trí (Position-wise Fully Connected Feed-Forward Network – FFN). Phương pháp này trích xuất hiệu quả các tính năng trình tự DNA tổng quát, cho phép phân loại hạ nguồn mạnh mẽ.
ViT sử dụng patch embedding để vector hóa mỗi hình ảnh bằng cách chia nó thành các patch và sau đó coi mỗi patch như một token. MHSA cho phép mỗi vị trí trong trình tự đầu vào chú ý đến thông tin ở các vị trí khác, từ đó cho phép mô hình hóa ngữ cảnh toàn cục mà không cần đưa vào thứ tự trình tự. Cơ chế đa đầu cho phép mô hình chú ý đến thông tin từ nhiều không gian con, nâng cao khả năng trích xuất tính năng phong phú hơn. - Huấn luyện trước bằng Masked Autoencoder (MAE): Mặc dù ViT vượt trội hơn CNN trong việc mô hình hóa thông tin toàn cục, nó yêu cầu nhiều dữ liệu huấn luyện hơn để đạt được khả năng khái quát hóa tương đương do có ít thiên kiến cảm ứng đặc trưng cho hình ảnh hơn. Trong lĩnh vực NLP và CV, huấn luyện trước tự giám sát (self-supervised pre-training) thường được sử dụng để giải quyết vấn đề thiếu dữ liệu.
Để có được biểu diễn tính năng phổ quát và mạnh mẽ hơn, PCVR sử dụng huấn luyện trước MAE. MAE21 cung cấp một phương pháp huấn luyện mạnh mẽ trang bị cho encoder khả năng nhận diện các mẫu phức tạp và thông tin cấu trúc trong hình ảnh. MAE sử dụng cấu trúc encoder-decoder bất đối xứng. Nó học tính năng thông qua nhận diện tính năng và tái tạo pixel. MAE kết hợp cơ chế che mặt (masking) tương tự BERT22 cho huấn luyện trước không giám sát.
Chiến lược che mặt ngẫu nhiên trong huấn luyện trước MAE cho phép mô hình học thông tin phức tạp từ hình ảnh. Encoder chỉ xử lý một tập hợp con các patch hình ảnh hiển thị, trong khi decoder xử lý cả đầu ra của encoder và các patch đã bị che mặt để tái tạo hình ảnh hoàn chỉnh. Chiến lược này giúp giảm rủi ro các patch được chọn tập trung gần trung tâm hình ảnh và ngăn mô hình dễ dàng suy luận các khối bị che mặt chỉ dựa vào các patch lân cận hiển thị, thúc đẩy mô hình học thông tin cấp cao hơn và phức tạp hơn giữa các patch hình ảnh.
Mục tiêu huấn luyện trước MAE là sử dụng Lỗi Bình phương Trung bình (MSE) làm hàm mất mát, tính toán bằng cách tổng bình phương khác biệt giữa các pixel gốc và pixel được tái tạo. Hàm mất mát chỉ được tính cho các patch bị che mặt. Mục tiêu là cho phép mô hình xác định các mẫu cụ thể trong FCGR, điều này rất cần thiết để encoder phân biệt các trình tự thuộc các lớp khác nhau bằng cách mã hóa chúng với ranh giới tính năng rõ ràng. - Tinh chỉnh cho Phân loại Phân loại học: Sau khi mô hình được huấn luyện trước nắm bắt được các mẫu trong tập dữ liệu, ViT encoder có thể đóng vai trò là bộ trích xuất tính năng hình ảnh cho nhiệm vụ phân loại tiếp theo. Mô hình ViT được huấn luyện trước được tinh chỉnh với một mạng perceptron đa lớp bổ sung để điều chỉnh cho nhiệm vụ phân loại trình tự DNA.
PCVR sử dụng một đầu phân loại phân cấp (hierarchical classification head). PCVR chuẩn hóa các tính năng đầu ra từ ViT để thu được tính năng toàn cục. Tính năng toàn cục này được sử dụng làm tính năng phân loại ở cấp siêu giới (superkingdom). Khi độ khó phân loại tăng lên ở các bậc phân loại thấp hơn (ngành – phylum và chi – genus), cần nhiều thông tin hơn. Do đó, cấu trúc tinh chỉnh phân cấp được áp dụng: kết quả phân loại của mỗi cấp được kết hợp với các tính năng toàn cục do encoder tạo ra để thu được tính năng tổng hợp, sau đó được đưa vào lớp tuyến tính ở bậc thấp hơn làm đầu vào. Bằng cách này, kết quả phân loại ở cấp cao hơn có thể cung cấp tham chiếu cho phân loại ở cấp thấp hơn, cho phép mô hình tận dụng hiệu quả thông tin nhãn từ mỗi cấp.
Mục tiêu tinh chỉnh là sử dụng cross entropy làm hàm mất mát cho mỗi bậc phân loại. Để tối ưu hóa hiệu quả, trọng số liên quan đến các hàm mất mát ở các cấp khác nhau được điều chỉnh.

Thực nghiệm và Kết quả
Các thí nghiệm được thực hiện trên ba tập dữ liệu: closely related, distantly related, và final datasets. Tập dữ liệu huấn luyện trước bao gồm gần 2.5 triệu trình tự DNA từ bốn siêu giới. Các tập dữ liệu tinh chỉnh được xây dựng để đánh giá khả năng khái quát hóa, đặc biệt là tập distantly related nơi không có sự trùng lặp chi giữa tập huấn luyện và tập kiểm tra.
Các mô hình PCVR (Base và Large) được so sánh với các phương pháp hiện có như MMseqs2, minimap2, DeepMicrobes, BERTax, Subspace KNN, và Bagged decision trees.
Trên tập closely related, PCVR-Large cho thấy sự cải thiện đáng kể về macro AveP so với BERTax. Đối với tập distantly related, PCVR đạt macro AveP vượt trội so với Subspace KNN. Trên tập final dataset, giá trị macro AveP cao hơn được thu được cho một tập dữ liệu lớn hơn so với tập closely related. Ở cấp chi (genus level), mặc dù không đạt hiệu suất tốt nhất, PCVR-Base vẫn vượt trội hơn BERTax.
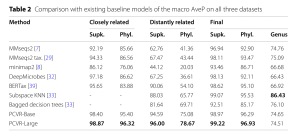
Bảng 2, nằm trong phần Thực nghiệm, trình bày kết quả so sánh hiệu suất macro AveP trên cả ba tập dữ liệu.
PCVR cho thấy hiệu suất xuất sắc ở cấp siêu giới và ngành, cho thấy khả năng nắm bắt các mẫu phức tạp trong trình tự. Hiệu suất vượt trội này được gán cho khả năng biểu diễn mạnh mẽ của FCGR và khả năng huấn luyện trước mạnh mẽ của MAE. Tuy nhiên, ở cấp chi, hiệu suất có thể bị ảnh hưởng bởi sự mất cân bằng lớp trong dữ liệu.
Ngoài macro AveP, các chỉ số đánh giá bổ sung bao gồm micro AveP, Accuracy (Acc), micro-averaged AUC, và Proportion of Predicted Samples (Prop) cũng được sử dụng.
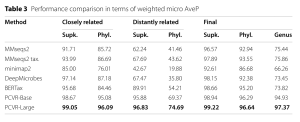
Bảng 3, nằm trong phần Thực nghiệm, hiển thị kết quả so sánh hiệu suất về micro AveP có trọng số.
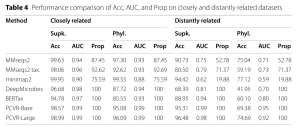
Bảng 4, nằm trong phần Thực nghiệm, trình bày kết quả so sánh Acc, AUC, và Prop trên các tập closely related và distantly related. PCVR vượt trội hơn các phương pháp dựa trên DL khác và đạt Acc tương đương với các phương pháp dựa trên căn chỉnh. PCVR cũng cho thấy sự mạnh mẽ vượt trội được minh chứng bằng AUC cao. PCVR khắc phục hạn chế về độ phủ phân loại thấp của các phương pháp dựa trên căn chỉnh bằng cách so sánh các mẫu tương đồng trình tự thay vì dựa vào căn chỉnh trình tự trực tiếp.
Các phân tích thống kê sử dụng kiểm định Wilcoxon signed-rank một phía cho thấy sự cải thiện hiệu suất của PCVR (Base và Large) là có ý nghĩa thống kê so với các mô hình cơ sở khác.
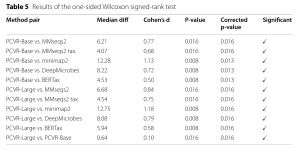
Bảng 5, nằm trong phần Thực nghiệm, hiển thị kết quả của kiểm định Wilcoxon signed-rank một phía.
Đánh giá và So sánh Encoder
PCVR vượt trội hơn BERTax trên tất cả các tập dữ liệu. Sự cải thiện đáng kể ở các bậc phân loại thấp hơn được cho là do sự mạnh mẽ của huấn luyện trước tự giám sát MAE và khả năng mạnh mẽ của ViT trong việc nắm bắt thông tin ngữ cảnh của các tính năng. FCGR cũng giúp các tính năng từ các loại khác nhau có sự phân biệt rõ ràng hơn so với việc sử dụng token 3-mer như trong BERTax.
Để đánh giá chất lượng biểu diễn trình tự DNA dưới sự kết hợp của FCGR và huấn luyện trước MAE, khả năng nhận diện của ViT encoder sau giai đoạn huấn luyện trước đã được kiểm tra bằng phương pháp truy xuất tính năng dựa trên xếp hạng tương đồng cosine.
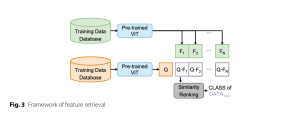
Hình 3, nằm trong phần Thực nghiệm, minh họa framework của truy xuất tính năng.
Kết quả truy xuất tính năng cho thấy encoder của PCVR thể hiện khả năng trừu tượng mạnh mẽ hơn đáng kể ở các bậc phân loại thấp hơn so với BERTax sau khi huấn luyện trước. Ngay cả khi không tinh chỉnh, PCVR-Base vẫn thể hiện hiệu suất vượt trội trên hầu hết các tập dữ liệu. Sau khi tinh chỉnh với thông tin danh mục, hiệu suất đã cải thiện đáng kể.
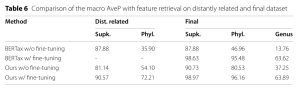
Bảng 6, nằm trong phần Thực nghiệm, so sánh macro AveP với truy xuất tính năng trên tập distantly related và final dataset, cả trước và sau tinh chỉnh.

Hình 4, nằm trong phần Thực nghiệm, hiển thị hình ảnh trực quan hóa các tính năng tiềm ẩn được gom nhóm của PCVR-Base và BERTax thông qua T-SNE. Ngay cả khi không có thông tin danh mục trước khi tinh chỉnh, PCVR-Base đã mã hóa thành công các tính năng với ranh giới danh mục rõ ràng hơn trong không gian hai chiều so với BERTax.
Đánh giá Phân loại Phân cấp
Để đảm bảo các lớp tinh chỉnh được tích hợp đúng cách, đầu vào của bộ phân loại ở mỗi cấp phân loại đã được đánh giá bằng cách sử dụng truy xuất tính năng.
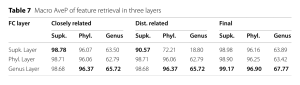
Bảng 7, nằm trong phần Thực nghiệm, trình bày macro AveP của truy xuất tính năng trong ba lớp (trước mỗi lớp FC).
Kết quả cho thấy việc tích hợp thông tin từ các cấp phân loại cao hơn có tác động tích cực đến dự đoán ở các cấp thấp hơn, đặc biệt là ở cấp chi (từ cấp ngành), dẫn đến tăng macro AveP trên các tập closely related và final datasets. Tập distantly related có kết quả khác biệt do không có các chi trong tập kiểm tra xuất hiện trong tập huấn luyện.
Nghiên cứu Phá bỏ (Ablation Study)
Các nghiên cứu phá bỏ được thực hiện để điều tra đóng góp của các thành phần khác nhau của PCVR đối với hiệu suất.
- Tác động của huấn luyện trước: So sánh ViT được khởi tạo bằng MAE pre-train, khởi tạo ngẫu nhiên, và khởi tạo từ ImageNet. Kết quả cho thấy MAE cung cấp trạng thái khởi tạo tốt hơn cho tinh chỉnh ViT, giúp mô hình hội tụ đến hiệu suất vượt trội nhanh hơn. Bảng 8, nằm trong phần Thực nghiệm, cho thấy tác động của khởi tạo encoder trên các tập distantly related và final datasets.
- Tác động của cài đặt huấn luyện trước MAE: Khảo sát tỷ lệ che mặt, số lớp và kích thước nhúng của decoder. Hình 5, nằm trong phần Thực nghiệm, so sánh các cài đặt decoder khác nhau về macro AveP trên cả ba tập dữ liệu. Kích thước nhúng của decoder có tác động, trong khi các cài đặt khác có tác động biên.
- Tác động của kích thước k-mer: Đánh giá các kích thước FCGR khác nhau tương ứng với k-mer 4, 5, và 6. Kích thước 5-mer được chọn làm đầu vào ưa thích cho mô hình do hiệu suất tổng thể trên tất cả các tập dữ liệu. Kích thước 6-mer đạt hiệu suất tốt hơn trên tập final dataset, cho thấy k-mer lớn hơn kết hợp thông tin trình tự bậc cao hơn. Bảng 9, nằm trong phần Thực nghiệm, trình bày nghiên cứu phá bỏ về k-mer trong FCGR trên các tập distantly related và final datasets.
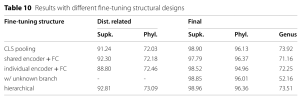
- Tác động của thiết kế kiến trúc tinh chỉnh: So sánh các cấu trúc tinh chỉnh khác nhau, bao gồm sử dụng token “CLS” pooling, lớp FC đơn giản, encoder chia sẻ/không chia sẻ, và nhánh “unknown”. Cấu trúc phân cấp và global pooling hiệu quả hơn. Bảng 10, nằm trong phần Thực nghiệm, trình bày kết quả với các thiết kế cấu trúc tinh chỉnh khác nhau.

- Tác động của trọng số mất mát: Khám phá tác động của trọng số mất mát phân loại ở các cấp phân loại khác nhau. Tỷ lệ trọng số 2:3:5 (siêu giới:ngành:chi) cho thấy sự cải thiện so với 3:3:3. Hình 6, nằm trong phần Thực nghiệm, minh họa tác động của tỷ lệ trọng số đối với mất mát phân loại trong quá trình tinh chỉnh.
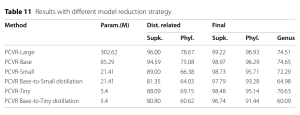
- Tác động của giảm mô hình: Khảo sát hiệu suất của các mô hình nhỏ hơn bằng cách áp dụng chưng cất (distillation) hoặc huấn luyện lại trực tiếp. Các mô hình lớn hơn có khả năng khai thác toàn bộ tiềm năng của PCVR tốt hơn. Bảng 11, nằm trong phần Thực nghiệm, trình bày kết quả với các chiến lược giảm mô hình khác nhau.

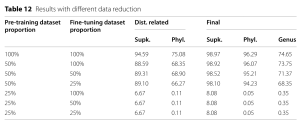
- Tác động của giảm dữ liệu: Điều tra tác động của khối lượng dữ liệu huấn luyện trước và tinh chỉnh. Giảm 50% dữ liệu huấn luyện trước vẫn cho hiệu suất tương tự trên tập final dataset, nhưng giảm đáng kể trên tập distantly related, làm nổi bật tầm quan trọng của huấn luyện trước đối với khả năng khái quát hóa. Bảng 12, nằm trong phần Thực nghiệm, trình bày kết quả với các tỷ lệ giảm dữ liệu khác nhau.

Nghiên cứu Trường hợp (Case Study)
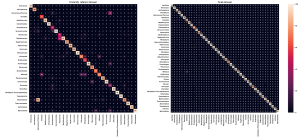
Hình 7, nằm trong phần Nghiên cứu Trường hợp, hiển thị ma trận nhầm lẫn của PCVR-Large cho bậc ngành trên tập distantly related và final dataset.

Hình 8, nằm trong phần Nghiên cứu Trường hợp, minh họa hình ảnh FCGR của các mẫu đúng dương, sai âm, đúng âm và sai dương. Các trường hợp này cho thấy PCVR có xu hướng dự đoán danh mục trình tự DNA dựa trên các mẫu phân biệt trong hình ảnh FCGR của chúng. Ví dụ, các trình tự có mẫu FCGR hình chữ thập thường được phân loại là “Streptophyta”, trong khi những trình tự thiếu tính năng này được gán cho “Arthropoda”. Tuy nhiên, các mẫu tương tự có thể tồn tại giữa các danh mục khác nhau, điều này cản trở độ chính xác phân loại của PCVR.
Thảo luận và Hạn chế
PCVR là một mô hình không dựa trên căn chỉnh, kết hợp ViT và huấn luyện trước tự giám sát MAE trên FCGR, đạt hiệu suất vượt trội so với các mô hình hiện đại ở cấp siêu giới và ngành, đặc biệt là trong các tình huống có khoảng cách giữa dữ liệu kiểm tra và huấn luyện. Bằng cách sử dụng FCGR, PCVR giảm sự phụ thuộc của mô hình vào độ dài và chất lượng dữ liệu. MAE pre-training giúp ViT nắm bắt các tính năng trừu tượng cấp cao trong FCGR, tiết lộ thông tin cấu trúc cục bộ và toàn cục trong trình tự DNA.
Hiệu suất tốt nhất ở cấp siêu giới và ngành, đặc biệt là trên tập distantly related, cho thấy khả năng học các mẫu của PCVR và tiềm năng ứng dụng thực tế. Điều này cũng minh chứng tiềm năng khái quát hóa và linh hoạt của ViT được huấn luyện trước trên phạm vi rộng hơn các nhiệm vụ hạ nguồn về trình tự DNA. Tuy nhiên, ở cấp chi, hiệu suất bị ảnh hưởng bởi sự mất cân bằng lớp trong dữ liệu.
So với BERTax, sự kết hợp FCGR+MAE vượt trội hơn tokenizer+BERT, cho thấy các phương pháp dựa trên biểu diễn FCGR đạt hiệu suất vượt trội khi được bổ sung bằng các bộ mã hóa hình ảnh phức tạp và chiến lược huấn luyện tốt. Điều này gợi ý rằng việc xem phân loại trình tự DNA như một vấn đề phân loại hình ảnh FCGR có thể phù hợp hơn là coi nó như một nhiệm vụ ngôn ngữ.
Trong nghiên cứu trường hợp, việc trực quan hóa các mẫu FCGR cho thấy PCVR phân loại dựa trên các mẫu thị giác. Tuy nhiên, sự đa dạng trong cùng lớp và sự tương đồng giữa các lớp về mẫu trình tự có thể dẫn đến sai sót phân loại.
PCVR vẫn còn một số hạn chế. Độ chính xác dự đoán có thể bị ảnh hưởng bởi phân phối mất cân bằng của dữ liệu tinh chỉnh. Hiệu suất của PCVR phụ thuộc vào việc huấn luyện trước, điều này yêu cầu tài nguyên tính toán. Một số thông tin trình tự bị mất khi sử dụng FCGR do nó chủ yếu trích xuất thông tin tần số. Việc tích hợp nhiều chiến lược mã hóa có thể là hướng đi trong tương lai để khắc phục hạn chế này.
Kết luận
PCVR là framework đầu tiên giới thiệu ViT vào phân loại trình tự DNA và thu được biểu diễn theo ngữ cảnh bằng MAE pre-training. PCVR tối ưu hóa việc mô hình hóa các phụ thuộc tầm xa và thông tin toàn cục trong trình tự DNA. Kết quả thực nghiệm cho thấy PCVR đạt hiệu suất vượt trội trên nhiều tập dữ liệu, cải thiện đáng kể độ chính xác phân loại trình tự DNA ở cấp siêu giới và ngành. Khả năng khái quát hóa và mạnh mẽ của PCVR mở ra một hướng tiếp cận đầy triển vọng cho việc khám phá loài mới và ứng dụng rộng rãi cho các nhiệm vụ bộ gen khác.
LOBI Vietnam là công ty tiên phong trong lĩnh vực Đọc trình tự gen thế hệ mới NGS (Next Generation Sequencing) và Phân tích Tin sinh học. Liên hệ hotline/Zalo 092.510.8899 để biết thêm chi tiết.
